
※この記事には広告リンクが含まれます。
はじめに
昨年末に登場したGPTsのデータ分析アプリ「Data Analyst」。この新しいツールは、一体どのような機能を持っているのか、実際に使用してその実力を検証してみました。Pythonの出力結果とData Analystの出力を比較して、どんなメリットやデメリットがあるのかを探求します。また、Data Analystの機能性や操作性などについても深掘りしていきます。

のびノーリ
この記事ではGoogle Colaboratoryを使用してPythonとGPTsのData Analystでのデータ分析結果を比較検証していきます。
ぜひ、最後まで読んでみて下さい!
分析データについて
今回はe-Stat(政府統計の総合窓口)から男女別人口-全国,都道府県(大正9年~平成27年)のデータが格納されているcsvファイルをローカル環境にダウンロードします。
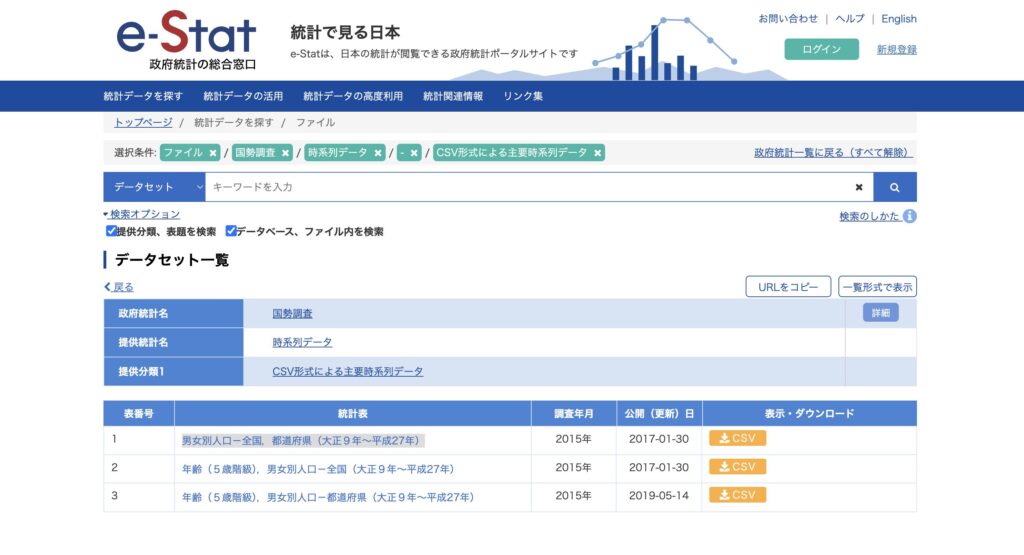
こちらのデータには都道府県別に1920年〜2015年までの男女別と総人口数が、5年刻みで入力されています。
この記事ではこちらのデータを使って検証していきます。
Python(Google Colab)での分析
今回はブラウザ上で使えるPythonの実行環境のGoogle Colaboratory(略称 Google Colab)を使って検証していきます。
この先の記事では略称のGoogle Colabで説明していきます。
Google ColabとGoogleドライブの接続
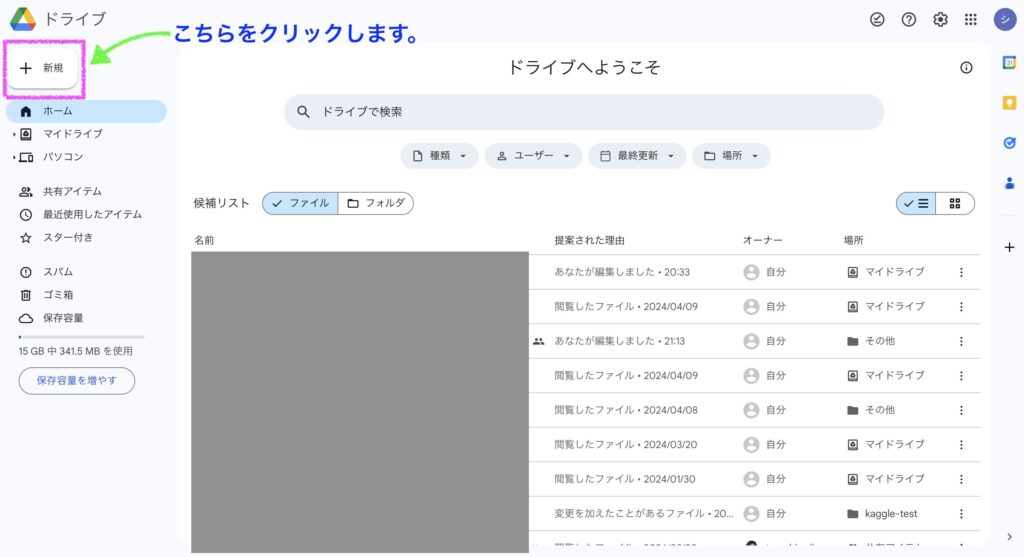
ここではGoogle Colabを呼び出し、Googleドライブと接続するまでの手順を、ステップを追って説明します。
この作業が必要になるのは、データファイルをGoogleドライブから読み込むことを前提にしています。
例えばローカル(PC)やGitHubからデータファイルを読み込む場合には、それぞれに対応したコードで読み込むことになりますのでご了承下さい。
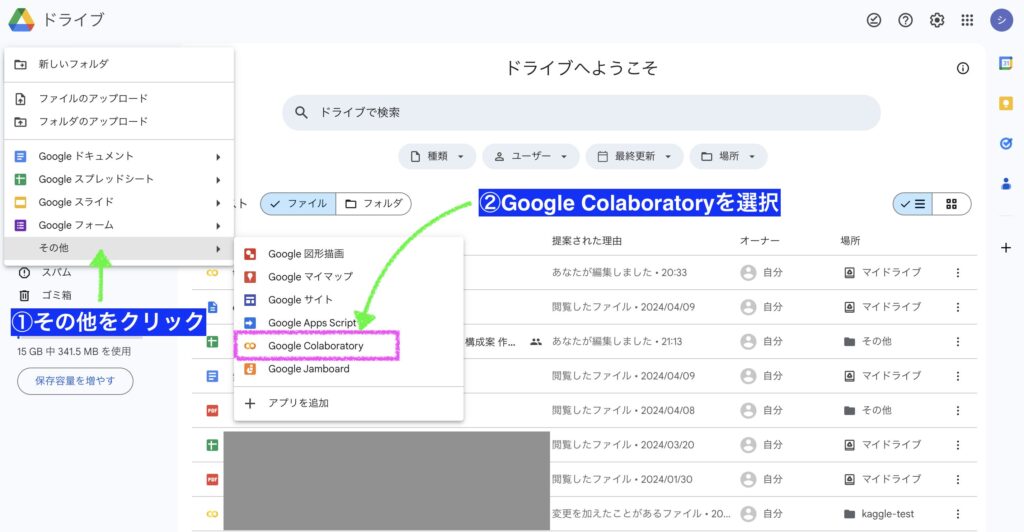
Googleドライブの「新規」タブをクリック
from google.colab import drive
drive.mount('/content/drive')上のコードによりGoogle ColabにGoogleドライブに保存しているファイルが読み込めるようになります。
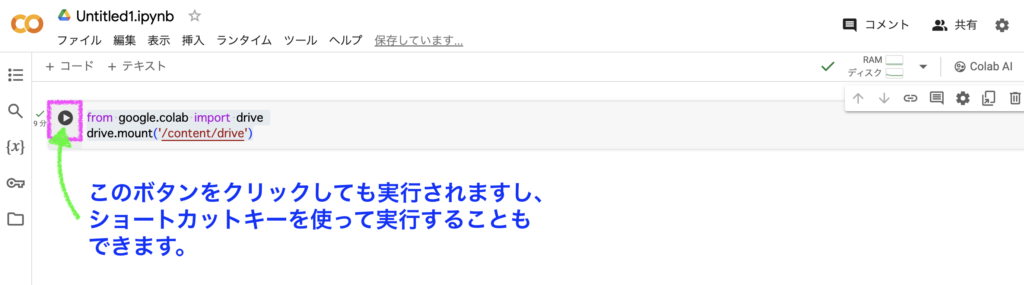
STEP3のコードを実行すると↓下の画像のようにメッセージが出現するので「Googleドライブに接続」をクリックします。
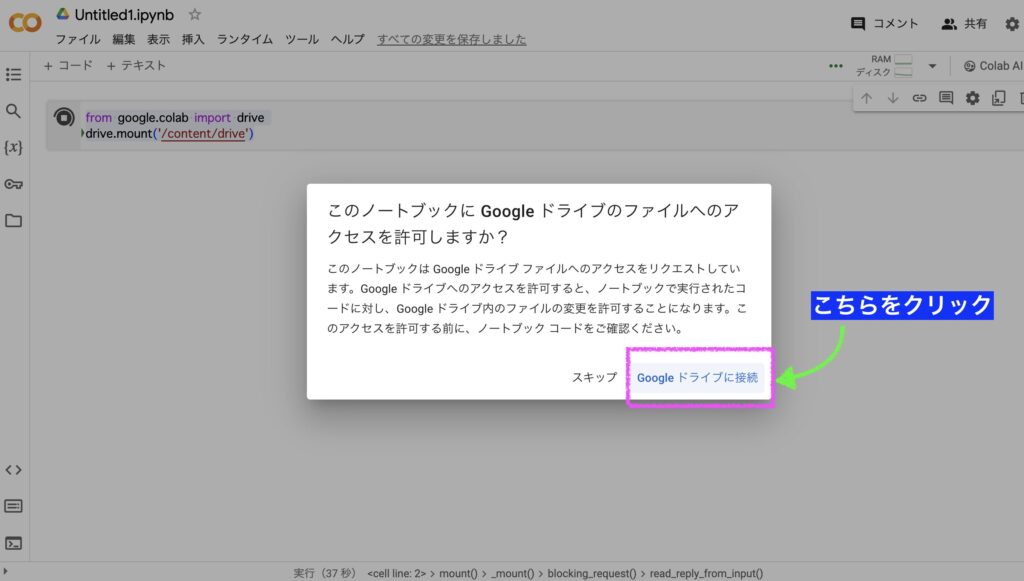
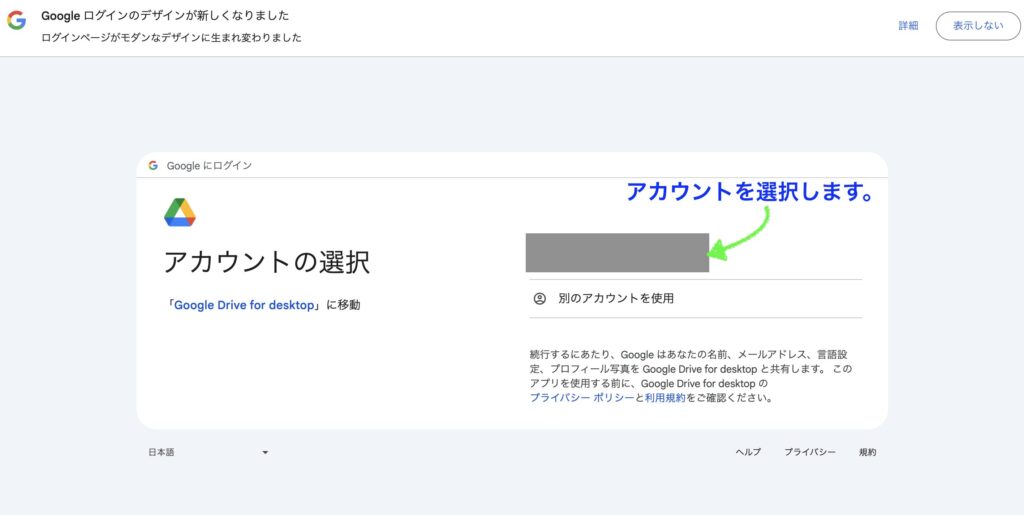
↓下の画像のようにGoogleアカウントの選択画面に遷移するのでファイルを保存しているアカウントを選択します。
↓下の画像にあるメッセージでマウントが完了したことを確認でき、Googleドライブに保存したデータが読み込めるようになります。
Googleドライブに保存したデータファイルの読込
それでは実際にGoogleドライブに保存したcsvファイルを読込みます。
その前にPythonのデータ解析用のライブラリであるPandas(パンダス)を下のコードを使ってインポートします。

次に日本語が含まれるデータなので、エンコードを「shift_jis」に指定してcsvファイルを読み込むメソッド(コード)を実行します。なお、ファイル名はc01.csvです。
データの前処理
試しに昭和から平成にかけて、北海道のデータを抽出して人口の推移を可視化してみることにしました。
データ分析を始めるにあたり、必ず含まれるデータの型は確認するようにしておくと、後々必ず役に立ちます。
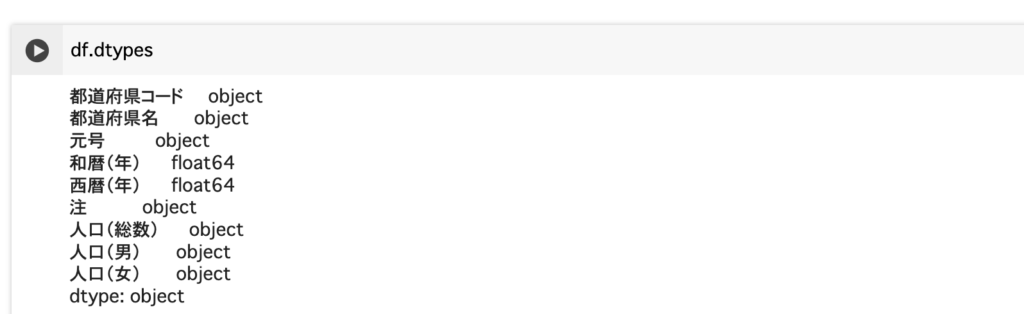
和暦(年)と西暦(年)がfloat64(浮動小数点型)以外のデータはobject型となっています。
このことから、人口のデータは数字とテキストが混在している可能性があることが分かります。
人口(総数)のデータを使おうと思うので、人口(総数)のデータをfloat64に↓下の画像にあるコードで変換します。

時系列データの抽出
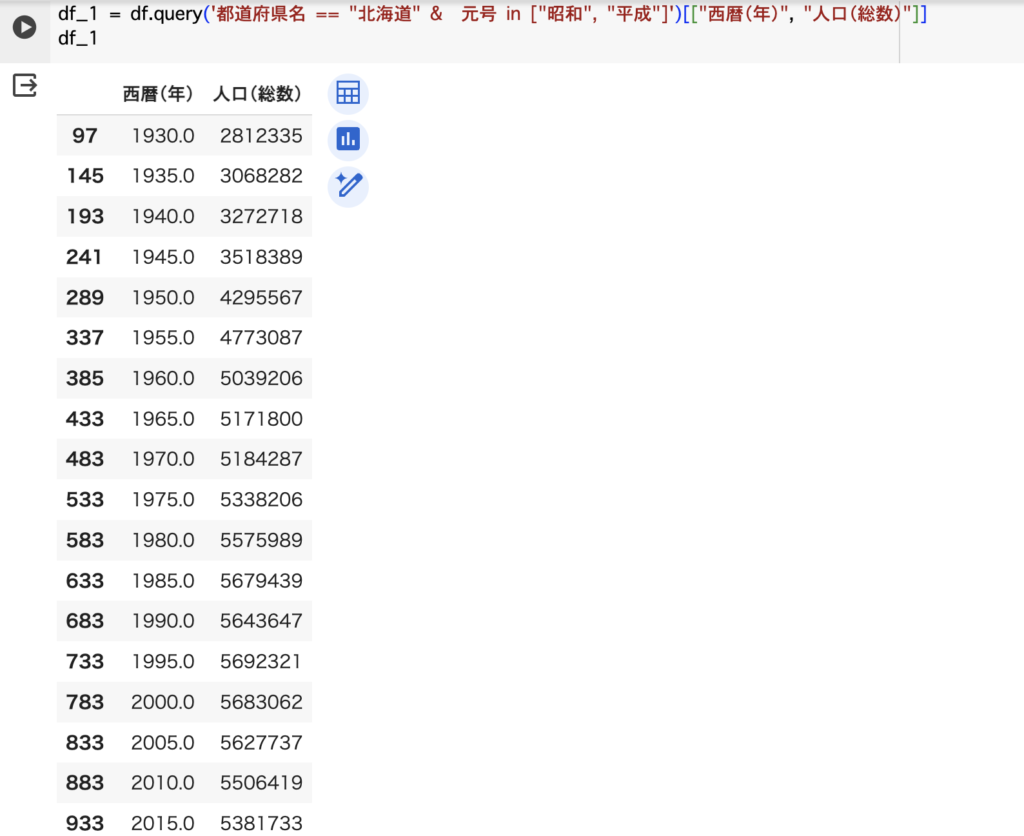
ここからが本番となり、北海道の昭和から平成にかけての人口(総数)のデータを抽出します。
queryメソッドを使って↓下の画像にあるコードでデータを抽出しました。
ただ、西暦で表示した方が表示するカラムを減らせるので、出力は西暦と人口(総数)のデータに絞りました。
抽出されたデータは、新たな変数のdf_1に代入しておきます。
抽出データの可視化
Pythonでデータ可視化ライブラリの代表としてMatplotlibですのでインポートします。
さらに日本語に対応させるためのjapanize_matplotlibをPiPコマンドでインストールしてインポートしておきます。
実はこのjapanize_matplotlibをインポートするということが肝だったりするそうです。

そして、df_1のデータを時系列のグラフに変換します。
↓下の画像にあるコードで、本当に必要最小限のコマンドにて描画しました。
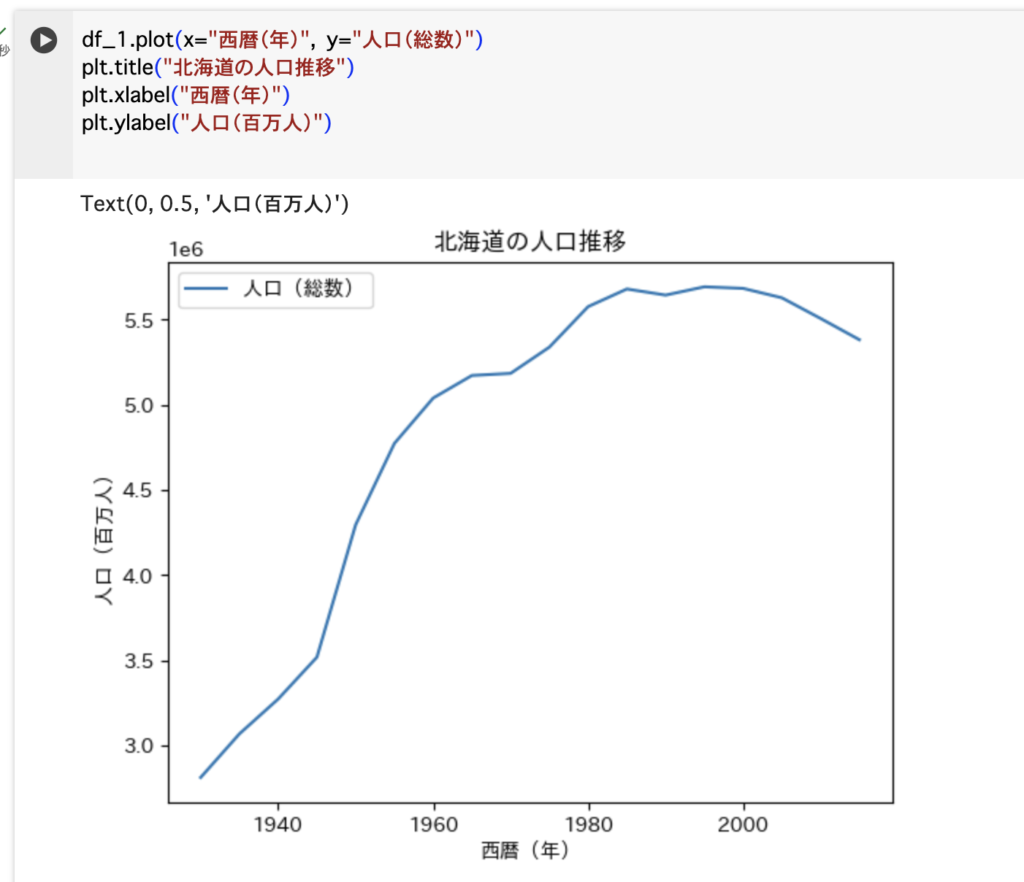
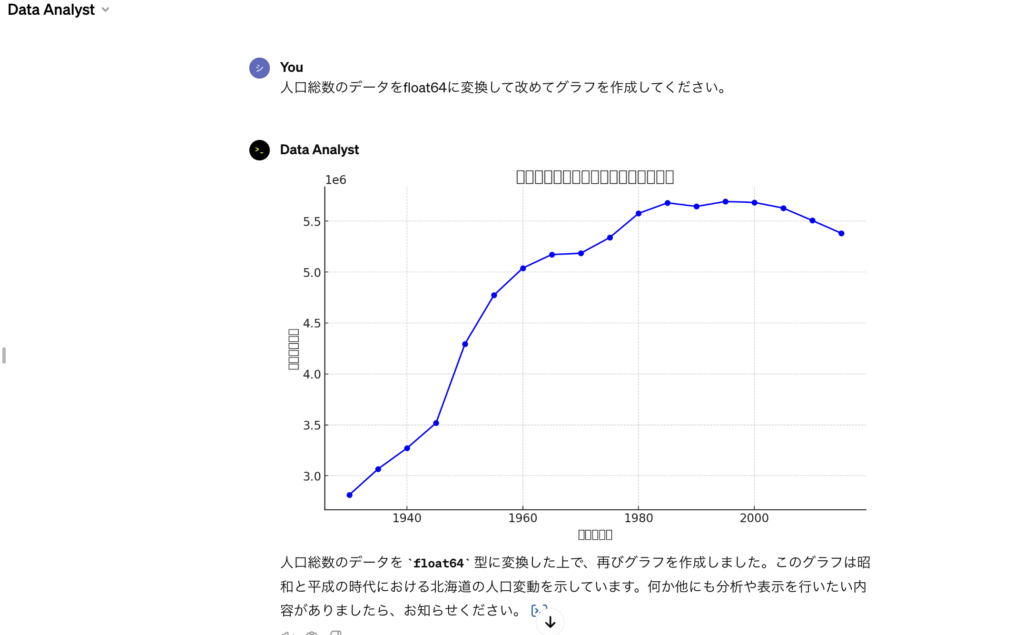
このグラフからも分かるように、1990年代にピークをつけて2000年以降は減少傾向にあることが見受けられます。
人口(総数)の最大値と最小値
最後にこのデータにおける最大値と最小値を確認します。
最大値と最小値は簡単に確認できるのですが、最大値及び最小値の時の西暦も一緒に出力させたかったため、インデックスを西暦にすることで実現させました。
↓そのコードがこちらです。
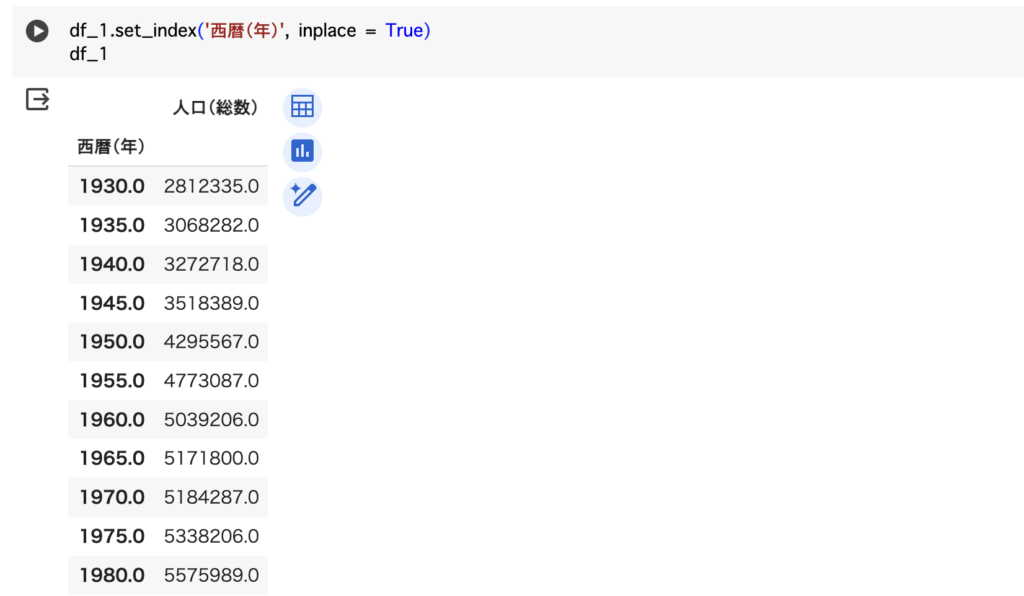
↓そして最大値と最小値を確認したコードがこちらです。
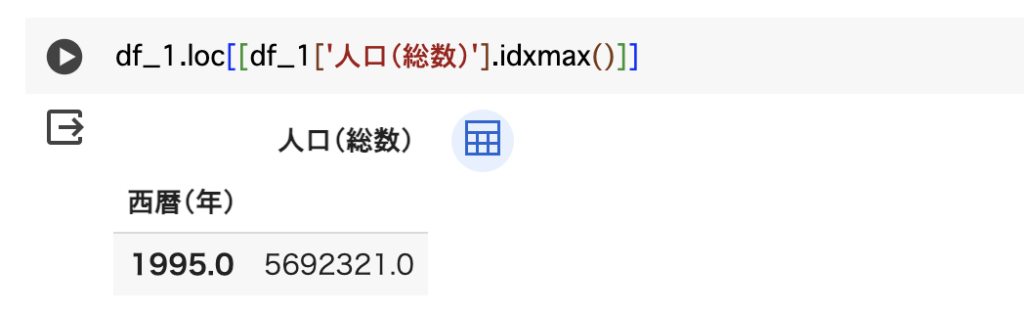
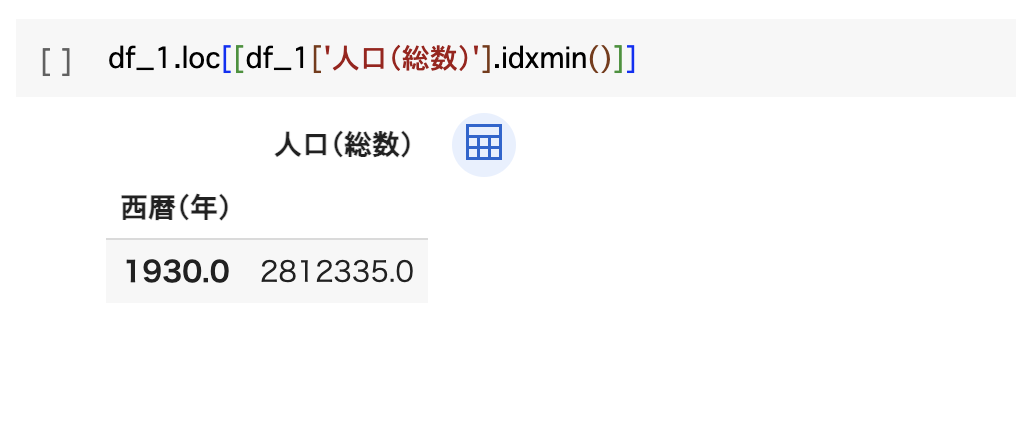
北海道の人口は1930年からすると1995年に約倍増してその後は減少傾向にあることが分かりました。
ここまでの分析結果が、GPTsのData Analystでどこまで再現されるかを検証していきたいと思います。
GPTsのData Analystを使ってみた
最初に、GPTsは課金プラン(月額20ドル)でしか使用できない機能ですのであらかじめご了承ください。
それではいよいよData Analystを使っていきたいと思います。
統計データのアップロード
先ずはPCに保存しているcsvファイルをアップロードします。
北海道に絞ったデータの抽出
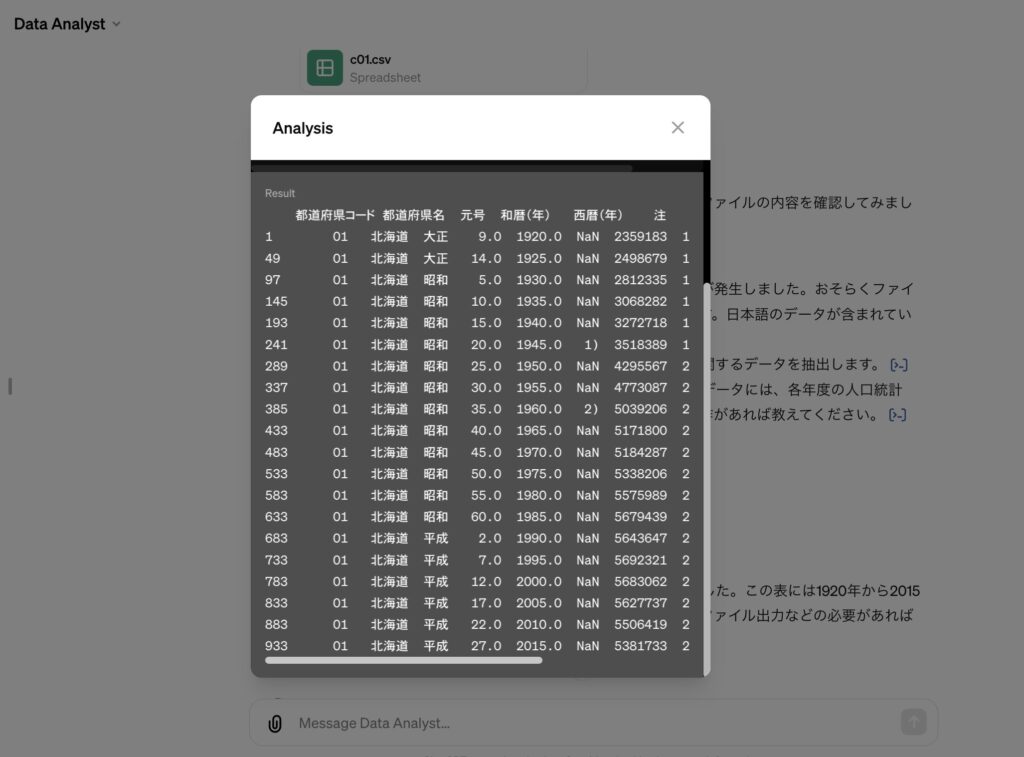
自然言語で「北海道のデータを抽出してください」とお願いするだけで、下の画像にあるように一旦エラーが発生したものの、AIが自力で解決して、ちゃんとデータを取得してくれました。
また、取得されたデータは下の画像で示した場所をクリックすると確認ができました。

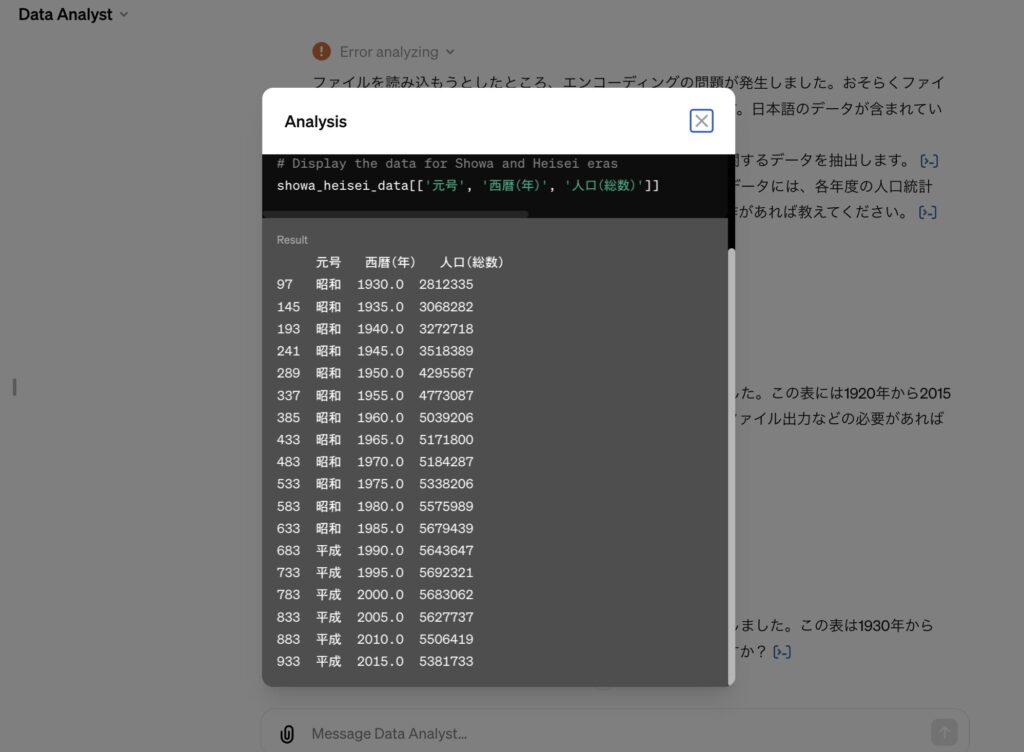
時系列での人口(総数)データの抽出
西暦及び和暦を指定して人口(総数)のデータを取得してくださいとお願いしました。
すると、お願いしたとおりにデータを取ってきてくれました。

時系列データの可視化
時系列での人口(総数)データはグラフ化することで、その特徴や傾向が一目瞭然となるのでこちらも自然言語で依頼します。
↓下の画像を見ても確認できるように、x軸やy軸を日本語表示にして欲しいとお願いしたのですが、上手く表示されていません。
さらにはグラフが直線になってしまっています。
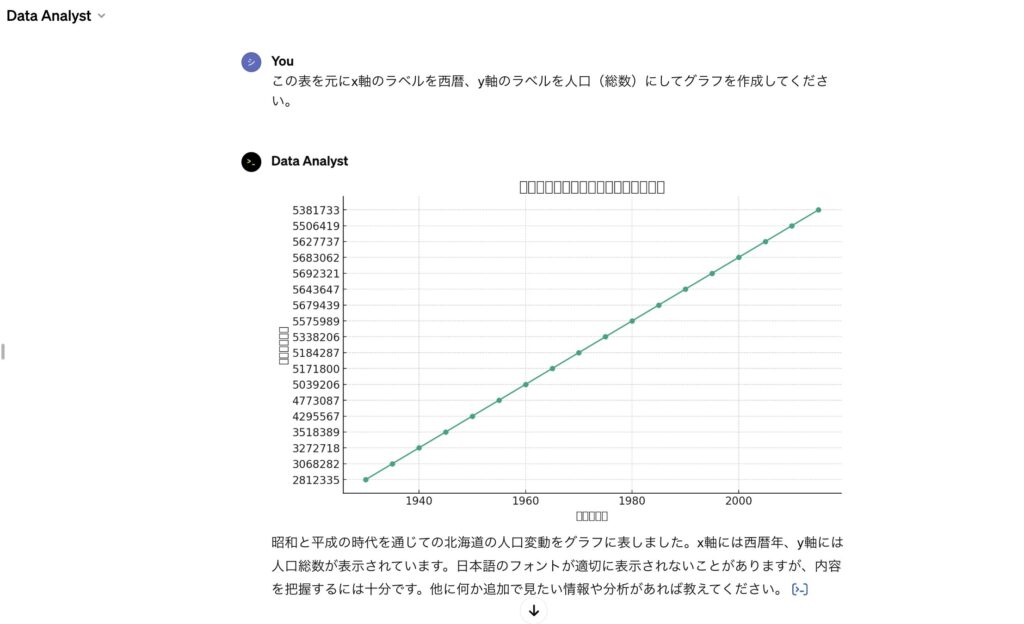
このグラフが直線になっているのは、人口(総数)データがobject型になっているため、数値として認識されていないことが原因だとPythonでトライした時に分かりました。
なので、人口(総数)データをfloat64型に変換してから改めてグラフの再表示をお願いしました。
すると↓下の画像のように人口推移が正確に反映されたグラフが作成されました。
さらにグラフタイトル、x軸並びにy軸の日本語表示を改めて依頼しましたが、こちらはどうしても対応してもらえませんでした。
人口(総数)の最大値、最小値の取得
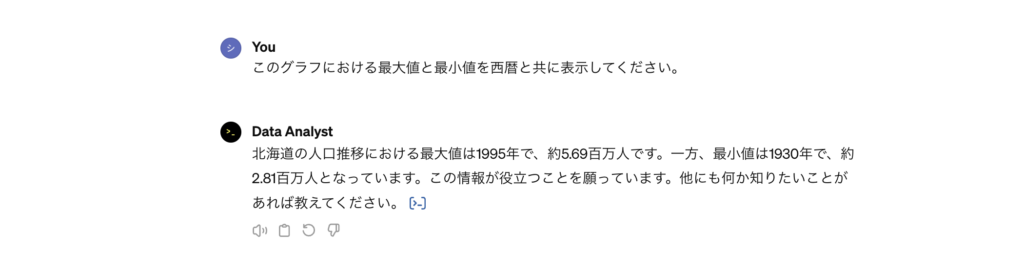
最後に指定期間内における人口(総数)の最大値と最小値の取得を試みました。
Pythonでは最大値と最小値は簡単に確認できるものの、その時に西暦を同時に表示させることは一手間かかりました。
GPTsで自然言語で試してみたところ、下の画像のように簡単な指示だけで正解を出力してくれました。
メリット及びデメリット
基本的にはPythonの分析結果とGPTsのData Analystの出力結果に大きな相違はなく出力はできましたが、やはり追加で指示が必要な出力結果も出てきました。
そこで、こちらの章ではData Analystのメリット、デメリットについてまとめます。
メリット
やはり間違いなくメリットに感じたことは下記の点です。
- 数多くのコードを叩くことなく、簡単な自然言語で精度高く分析が可能になることは大きなメリット。
- Pythonと比較すると分析にかかる時間が圧倒的に短縮される。
- AIが自力でエラー解決をしてくれる。
デメリット
残念ながら下記の点はまだ改善の余地があり、チェックが必要になりそうです。
- グラフ作成においてPythonでは日本語対応が上手くいったものの、Data Analystでは日本語表記に対応できなかった。
- objectデータをそのままグラフ化してしまっていたので、やはり出力結果をそのまま鵜呑みにしてしまうことにはまだまだリスクを伴う。
- やはり意図する出力に近づけるためにも、ファクトチェック並びにハルシネーションの見極め、更にはプロンプトの見直しはまだまだ必要である。
まとめ
Google ColabにてPythonによるデータ分析結果を導くのにはエラー解決も含めかなりの時間を要しました。
ただ、これは私がまだエントリーレベルのエンジニア相当のスキルしか持ち合わせていないからかもしれません。
一方でGPTsのData Analystによる分析は不具合箇所の修正指示も含めて30分程で、Pythonで導いた結果にかなり近づいた出力が得られ、その実力にはただただ驚かされるばかりでした。
まだまだ、完璧な出力結果を望むことはできないとしても、これらのAIツールをどうやって上手く使いこなすかが、今後変化し続ける環境に上手に適応するためにも肝要になると思います。
※追記
↓GPT4oでデータ分析をして、GPTsのData Analystの実力と比較検証した記事や、PDFファイルのデータ読込からデータ集計や可視化についてもまとめましたのでご一読下さい。


のびノーリ
まだまだAIの進化は発展途上だと思います。
情報のキャッチアップは欠かせませんね!
ここまで読んでくださった方、ありがとうございました!
また、次回の記事でお会いしましょう!

